かなり長い前置き。
Windows 10 HomeにインストールしたEmacs 26.2(MinGW版)を使ってPlay framework+Scalaで実装したログイン認証とかセッションとか、データベースへの読み書き及び追加並びに削除機能を備えたものすごく簡単な(※無理解な周囲の発言です。)Webアプリケーションを作ろうと2週間ほど格闘した結果…
なんとか動きました!!
長かった… (ノД`)
Emacsでの作業を行うにあたり、使用感を統合開発環境におけるものにできるだけ近づけるために、開発作業と並行して、
- neotree: ディレクトリ構造の階層表示。
- Metals: 入力補完。
- 独自開発のツール: データベースの定義からデータベースへのアクセス用のScalaのコードを出力する簡易ツール。コマンドラインで使用する。
をインストールしたり作成したりして用意をしました。
本体のWebアプリケーションの開発作業の方はおかげさまで無事終了いたしましたが、Emacsの設定作業に励んでいるうちに、
「ファイルを跨いだファイルの中身の検索機能(日本語の文字列が検索できれば尚可)」
がないのが徐々に気になりだしました。
そこで、「Emacs grep」的な検索語でGoogle先生にお伺いを立ててみたところ、「rgrep」なるものがあることを発見。
「これだ!!🎯」と思い、
Emacsに #rgrep なるものがいつの間にか追加されていて、ディレクトリ内のファイルの中身を再帰的に検索できることを今知った件。
Windows上でもUnixと同様の機能を持つgrepコマンドのパスを設定することで動かせるようです。
個人ベースで #Scala でコードを書くときに使えそうです。#lifeinyokohama pic.twitter.com/gXJf9sul1q— pandanote.info (@Pandanote_info) September 23, 2019
スポンサーリンク
…と、うっかりツイート🐵してしまいましたが、日本語の検索を行うためにはちょっとした工夫が必要であることが判明しました。
そこで、工夫をしてみることにしました。
さっそく工夫してみた。
まず、lgrepが使えないか調べます。
Windows標準のgrepはUnixのgrepと仕様が異なることと、日本語の文字列に対応させるために、lvのシンボリックリンク版であるlgrepをインストールして使うことを試みました。
しかし、ビルドができなかったり、Windows標準のコマンドプロンプトで直接使えなかったりしたので、使用を断念しました。
ripgrepの登場です。
lv,lgrepが使えないということで、ちょっと絶望的な気分になりながら、それら以外にWindowsで使えるものがないか調べてみたところ、ripgrepなるものを発見しました。
grepよりも高速であることがウリのようですが、今回の設定の趣旨的にはUTF-8対応でかつ、MSYS2やCygwinが不要であることの方が本Webサイトの管理人たるpandaの興味を引きました。🐼
ripgrepのインストール
そこで、ripgrepをインストールしてみることにしました。
開発元のWebサイト(GitHub)を見に行くと、いろいろなインストールの方法が記述されていて、使う側の関心の高さを伺わせますが、以前Metalsのインストール及びセットアップを行った際にscoopをインストールしたので、Windowsのコマンドプロンプトから以下のコマンドを実行してripgrepをインストールします。ripgrepの実行ファイルは、rg.exeという名前でインストールされます。
なお、scoopをインストールしていない別のPCで、MSVCでビルドされているexeファイル(rg.exe)をダウンロードして適当なディレクトリにコピーして使ってみましたが、問題なく動作することを確認することができました。
Emacsから起動するための設定。
ripgrepがインストールできて動作確認ができたら、Emacsから起動するための設定を行います。
%HOME%\.emacs.dの下にあるinit.elに以下の設定を追加します。findコマンドについてはたまたまインストールされていたGit for Windowsに同梱のものを利用しています。また、nullデバイスを設定するとエラーとなってしまうので、設定を行わないこととしました。
grep-program “\”C:\\Users\\pandanote\\scoop\\shims\\rg.exe\””
grep-use-null-device nil)
さらに、サブプロセスに渡すパラメータの文字コードを cp932 にするための設定として、以下の設定も前述のinit.elに追加します(ここの設定例をほぼそのままコピペしています)。なおCygwinは使用していないため、Cygwin関連の設定は行いませんでした。
(setenv “LANG” “ja_JP.UTF-8”)
(set-file-name-coding-system ‘cp932)
(setq locale-coding-system ‘utf-8-unix)
;; プロセスが出力する文字コードを判定して、process-coding-system の DECODING の設定値を決定する
(setq default-process-coding-system ‘(undecided-dos . utf-8-unix))
;; サブプロセスに渡すパラメータの文字コードを cp932 にする
(cl-loop for (func args-pos) in ‘((call-process 4)
(call-process-region 6)
(start-process 3))
do (eval `(advice-add ‘,func
:around (lambda (orig-fun &rest args)
(setf (nthcdr ,args-pos args)
(mapcar (lambda (arg)
(if (multibyte-string-p arg)
(encode-coding-string arg ‘cp932)
arg))
(nthcdr ,args-pos args)))
(apply orig-fun args))
‘((depth . 99)))))
rgrepの動作確認。
ここで、Emacsを起動してrgrepの動作を確認してみます。
下図の赤矢印のディレクトリ(srcディレクトリ)の下にある拡張子が”scala”のファイルを再帰的に検索し、日本語の文字列を含む行を表示させてみます。
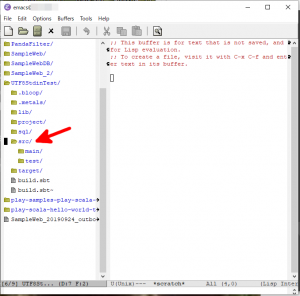
検索は以下の手順で実行することができます。
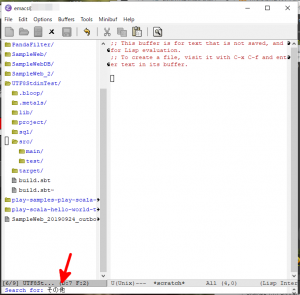
M-x rgrepと入力し、Enterキーを押します。- Emacsのミニバッファ(以下、単に「ミニバッファ」と書きます。)に”Search for:”と表示されますので、日本語の文字列を入力します。ここでは「その他」と入力し(下図の赤矢印)、Enterキーを押します。
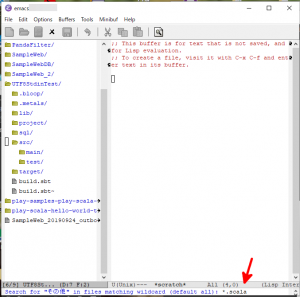
- ミニバッファに以下のように表示されますので、”*.scala”と入力し(下図の赤矢印)、Enterキーを押します。
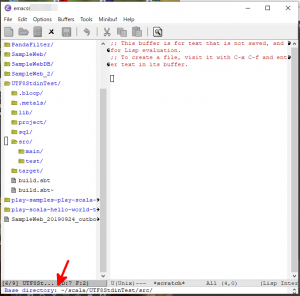
- 検索を開始するディレクトリの入力を要求するメッセージ(下図の赤矢印)がミニバッファに表示されますので、必要に応じて修正し、Enterキーを押します。
- すると、検索が実行されてその結果が2つに分割されたバッファの片側に表示されます。バッファの最初の方はEmacsから起動されたコマンドが表示されますが、スクロールすると検索の結果が表示されます(下図の赤矢印)。
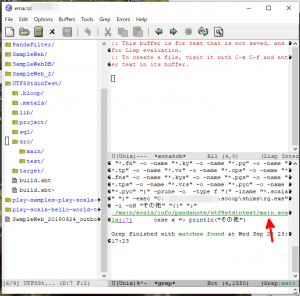
- 検索の結果として表示されるファイル名の部分(上図の赤矢印)をクリックすると、もとのバッファにそのファイルの中身が表示され、検索語として指定した文字列と一致する行が表示されます(下図の赤矢印)。
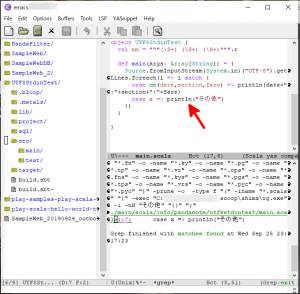
ここまでの手順で、rgrepの動作を確認することができます。
まとめ
ScalaはJavaよりも簡潔にコードを記述できますが、それでもコードの量が増えてくると、どこに何か書いてあったのかが次第にわかりにくくなることが予想されます。
そんなときに、rgrepによる日本語の検索が可能であることがわかっていれば、Scalaのコード中に日本語のコメントを書いておくことで、日本語によるコメントの検索を介して目的とするコードに容易に到達できるようになります。
統合開発環境のかわりにEmacsを使ってプログラムを書いた場合でも目的のコードに容易に到達できるようになるのであれば、コードの捜索によるコーディング作業の効率の低下を防ぐことができそうです。
この記事は以上です。
 Windows 10+Emacs 26+SBT-1.3.0-RC1でScalaの統合開発環境のようなものを整備してみる。
Windows 10+Emacs 26+SBT-1.3.0-RC1でScalaの統合開発環境のようなものを整備してみる。  Play framework (2.7.3)を使って構築したWebアプリケーションのカスタムエラーページにmessagesファイルで設定した文字列を表示する。
Play framework (2.7.3)を使って構築したWebアプリケーションのカスタムエラーページにmessagesファイルで設定した文字列を表示する。  Scalaのバージョンを新しくしたら、Metalsの更新も忘れずに行うべきであると信じる件(付録つき)。
Scalaのバージョンを新しくしたら、Metalsの更新も忘れずに行うべきであると信じる件(付録つき)。  Emacs 27.2をWindows 10のPCにインストールし、ついでにScalaの開発環境を再整備したり等してみた。
Emacs 27.2をWindows 10のPCにインストールし、ついでにScalaの開発環境を再整備したり等してみた。