はじめに
Scalaで書いたコードでそれなりにまとまった機能が実現できるようになり、実運用を行う日が近づいてきました。
Scalaではループ処理とタプルをうまく使うと、Javaよりもかなり効率のよい実装ができます。かつプログラムが横長になります↓

また、処理の種類によってはコードか読みやすくなる場合さえあります(この記事ではこの点についての詳細は割愛します)。
そこで、この記事ではループ処理についてはちょっと脇に置くことにして、タプルについて大いに語ります。✨
タプルとは?
タプルと言っても、タピオカの親戚とかということではなく、プログラミングの世界でタプルといえば、
「順序付けられた要素の列」
のことを指します。
Scalaでは、以下のような感じで定義します。
val a:(Int,String)=(3,"横浜市")
タプルはListにもできます。
val a:List[(Int,String)]=List((3,"横浜市"),(2,"川崎市"),(1,"相模原市"))
数列っぽいですね。
タプルのどのへんが良いのか?
スポンサーリンク
Javaとの比較になりますが、タプルを使うことの利点としてすぐに思いつくのは「3個以上の要素が一組になっているデータを扱うためにそれらのデータ専用のPOJO(Plain Old Java Object)を書かなくても良いこと。」ぐらいかなぁ… と思います。また、2個の要素が一組になっている場合にはMapインターフェースを実装するクラスを使って何とかする方向になるでしょう。
Javaの場合
しかし、よーく考えると…
POJOを書くということはクラスを作ることであり、それに対応した名前や作ったクラスを収容するためのパッケージ名を決めてやる必要があります。そのクラスに属する要素については対応する変数名も考えなければなりません。しかも、これらの名前はすべて開発者が独自に決めたものということになるので、事と次第によっては他の人に説明をするためのドキュメントを書かねばならなくなるかもしれません。
例えば、「2駅間の駅名及び運賃のリスト」を格納するための変数をJavaのプログラムで定義することを考えます。この場合、最初に2駅間の駅名及び運賃を格納するためのPOJOを定義して、そのクラスにFareみたいなクラス名を与え、そのクラスに属する3個の変数にstation1,station2,fareと命名することになると思います。次に、リストについてはJavaのListインターフェースを実装したクラスを用いて、
List
とプログラム中で定義することになります。なお、上記の変数の中身については別途Fareクラスのインスタンスを生成してfareListにaddメソッドで追加することになります。ただ、上記のFareというクラスの定義を他の人が見たり、後から見直してみたときに、これが何を表しているのかはドキュメントを見ない限りわからないと考えるのが一般的なところでしょう。
あるいは、上記のコードは実は何回か途中下車をするために切符をその都度買いなおすことになる場合に、最も安くなる経路を探すためのコードの一部であるかもしれません。この場合、Fareというクラスはある区間の運賃を探索するためのメソッドの内部でしか使われないので、開発者自身がわかっていればよいし、最悪クラスの仕様については忘れてしまっても動けばよいという位置づけになるでしょう。しかし、逆にその程度の重要度しか持たないクラスであるならば、クラスや変数の名前を決めたり、POJOを書いたりすることは意味のない作業に思えます。
そこで、タプルの登場です。
一方、Scalaのタプルで「2駅間の駅名及び運賃のリスト」を格納するための変数を定義する場合、以下のように変数に格納するデータもまとめて書くことができます。
val fareList : List[(String,String,Int)] = List(("A駅","B駅",136),("A駅","C駅",210))
ScalaのREPLでは以下のような感じで定義できます。
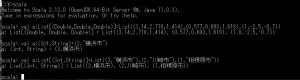
上記のリストについてのドキュメントを書く場合、厳密には「2駅間の駅名及び運賃のタプルのリスト」と書くべきかもしれませんが、「タプルの」を省いてしまっても(自然言語的には)意味のある文章になります。そこには開発者が独自に決めたクラス名などのネーミングが入る余地はありませんし、そもそもネーミングの必要がありません。
本Webサイトの管理人たるpandaの経験上、まとまった機能を持つソフトウェアを作る時に三つ組以上のデータの組を扱う実装をせねばならなくなった場合、それは1回で終わるものではなく、別の箇所でも必要になることが多いように感じます。Javaの場合であればPOJOを作ってそのネーミングを考える作業は短小な作業になりますので、それを繰り返し行うことによるモチベーションの低下や、POJOが乱立することによる運用時の管理コストの増大を招きがちですが、タプルが使えるScalaではそのようなことは起こりません。
この節の最初の方で、2個の要素が一組になっている場合にはMapクラスを使って何とかする方向になると書きましたが、2個の要素の片方がkeyでもう片方が対応する値(value)のようなある種の上下関係がある場合には、Mapインターフェースを実装するクラスが使えます。しかし、2個の要素間の関係が対等である場合にはJava標準のクラスにはないBiMap(guavaにあります。)を使うなどの対応が必要になります。したがって、要素が2個の場合でもタプルを使っておいた方が、要素間の関係を気にすることなくコードを書くことができそうです。
使用例: A1形式から(row,cell)のタプルへの変換
ここで、Apache POIでMicrosoft Excel(以下単に「Excel」と書きます。)のセルにデータを読み書きする場合に頻出のA1形式から(row,cell)のタプルへの変換を行うコードをScalaで書くことを考えます。なお、(row,cell)の値はApache POIのgetRowメソッドやgetCellメソッドの引数として直接指定できる値とします。
通常Excelのセルは各列に付されているアルファベットと行番号を連結した文字列で表されます。
この表現形式を「A1表現形式」と呼ぶのだそうです。
「TLVフォーマット」と同じくらいの安直なネーミングですが、そう呼ぶものだそうなので、致し方ありません。
Apache POIは我が国🇯🇵ではExcelのセルにデータを読み書きする場合には格別に絶大な威力を発揮します。
実はApache POI内にA1形式からR1C1形式への変換、及びその逆の変換を行うクラスとしてCellReferenceというものが存在しますが、この記事におけるここまでの考察によりクラス名を覚えること自体に価値を感じなくなってしまったので、そのままScalaでコードを書いてみます。Apache POIはJavaで記述されていますが、Javaで記述されているということはScalaのコードからでもメソッドの呼び出しができるというわけです。
例によって前置きが長くなりましたが、コード例は以下のような感じになります。
上記のメソッドで変換されるタプルの各要素に1を加算してから文字列を作成する以下のようなコードをメソッドの呼び出し側で追加するとR1C1形式に変換できます。
val r1c1 = toRowCell(c,r.toInt)
"R%dC%d".format(r1c1._1+1,r1c1._2+1)
まとめ
いったんボツにしたはずのネタですが、ネタの方向性をちょっと変えた上でのまさかの復活です↓
Apache POIにCellReferenceというクラスがあるのを知らずに、 #Scala でA1形式とR1C1形式の間の変換用のコードを書いてしまった件。
この件でpanda大学習帳の記事を書いていたのですが、車輪の再発明を盛大にやらかしたので、コード自体は使いますが、記事としてはボツにしました。😅#lifeinyokohama— pandanote.info (@Pandanote_info) October 17, 2019
Javaで書くとそれなりの手間とコード量を要する処理は他にもループ処理界隈を始めとしていくつかありますが、本Webサイトの管理人たるpandaのScala力の都合により、この記事ではタプルについて書いてみました。
タプルを使うかどうか迷った時にはこの記事を思い出していただけると幸いです。
この記事は以上です。
 Eclipse+SBTでScalaのテストコードを書いて動かそうとしたところ、かなりハマったのでメモ。
Eclipse+SBTでScalaのテストコードを書いて動かそうとしたところ、かなりハマったのでメモ。  Eclipse+SBTで実行用JARファイルをビルドして、スタンドアロンで動かしてみた。
Eclipse+SBTで実行用JARファイルをビルドして、スタンドアロンで動かしてみた。  Windows 10+Emacs 26+SBT-1.3.0-RC1でScalaの統合開発環境のようなものを整備してみる。
Windows 10+Emacs 26+SBT-1.3.0-RC1でScalaの統合開発環境のようなものを整備してみる。  Windows 10 Homeでsbt-assemblyを使ってFat JARファイルを作ったところ、パスの文字列長が長すぎてクラスファイルが不足していて実行できなかった件。
Windows 10 Homeでsbt-assemblyを使ってFat JARファイルを作ったところ、パスの文字列長が長すぎてクラスファイルが不足していて実行できなかった件。