はじめに
この記事の続きになります。
GitHub Pagesを本Webサイトのサブドメインとして使用できるようにしましたので、この記事ではそのトップページっぽいものを作成していきます。
まず、ネタを考えます。
ネタといっても最初から新規に考えるのではなく、今までに記事を書くときにネタにしたものの中から使えそうなものを探すことにします。
ところがどっこい、使えなさそうなものならたくさんあるわけです… (´・ω・…
そんな中から、YouTube Data API (v3)を使ってpandanote.infoチャンネルの動画の一覧のページを作り、それをトップページとしてGitHubに半自動でアップロードするシステムを作ってみることにしました。
ところで、YouTube Data API (v3)って何ですか?
…という方もいらっしゃると思いますので、そんなこともあろうかと以下の記事を書いておきました。拙稿ではありますがご覧いただけると幸いです。
仕様を考えます。
処理の手順を考える。
YouTubeのデータをGitHub Pagesで使える形式に変換する処理を以下の手順で行うことを考えます。
- (初回のみ)GitHubにWebサイト用のリポジトリを作成します(こちらをご参照いただければと思います)。
- git clone(初回のみ)またはgit pullを実行して、ローカルのPC等にリポジトリの中身をダウンロードします。
- YouTube Data API (v3)を使ったプログラムを実行して、必要な情報を取得します。
- 手順3で取得した情報と別途用意しておいたmarkdown形式のテンプレートファイルを組み合わせて、トップページ用のmarkdownファイルを作成します。
- git commitします。
- git pushします。
- pushしたmarkdown形式のファイルはGitHub PagesのJekyllがコンパイルしてくれます。コンパイルには数分程度の時間がかかることがありますので、気長に待ちます。
- コンパイルが正常に終了すれば、ページが表示されます。
運用の方針を考える。
運用と言うほどのものではないかもしれませんが、前節で書いた処理を一撃で実行できるシェルスクリプトを準備して、当面の間はFedoraのPCから適宜手動で実行します。
YouTubeは少なくとも本Webサイトほどは更新を行いませんし、APIを用もなく呼び出しまくるようなシステム設計にはできないので、自動で実行するにしても1日1回程度の実行を前提とすることにします。
YouTube Data API (v3)を使ったデータ取得用プログラムの実装例。
実装例は以下の通りになります。例によってgoogle-api-python-clientを利用しています。
[2018/11/03追記] 164行目のISOフォーマットへの変換部でタイムゾーンが表示できていなかったので、タイムゾーンを表示できるようにコードを修正しました。
使用上注意した方が良いと思われる点は以下の通りです。
- thumbnailはytimg.comから取得しています。APIでも取得できますが、好みの問題です。
- 1回のAPIリクエストで取得できる動画の情報は50件までです。50件を超える動画の情報を取得したい場合にはnextPageTokenやprevPageTokenの値として返されるトークンを使用するようなのですが、pandanote.infoの動画の投稿件数がそこまで達していないということもあって、使ってみたことがありません。
- サンプルコードをそのまま実行すると、非公開や限定公開に設定した動画のタイトルや説明も取得できてしまうので、privacyStatusの値を確認して、それが”public”である動画のみ出力の対象としています。
privacyStatusの取り得る値は以下の通りです。- public: 公開
- unlisted: 限定公開
- private: 非公開
上記以外の細かい調整。
favicon
本Webサイトと同じfaviconをリポジトリのトップディレクトリに置きました。
“Developed with YouTube”ロゴの配置
YouTube API ServicesのBranding Guidelinesによりますと、APIを使って開発を行った場合には”Developed with YouTube”ロゴを表示すべきであると書いてあるような気がしますので、”Developed with YouTube”ロゴのPNGファイルをここからダウンロードして、サイズを変更した後でリポジトリのトップディレクトリに置き、”Developed with YouTube”ロゴをページのタイトルと本文の間に入れてみました。
スポンサーリンク
これはこれで、ページが引き締まった感じがします。(`・ω・´)
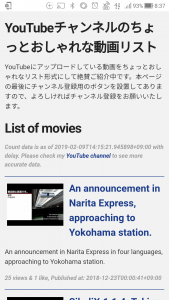
Webサイトの出来上がりです。
Webサイトはこんな感じになりました。どちらかというとスマホで見たほうがカッコよく見えますね。
PCで表示したときのWebサイト作成時点でのスクリーンショットは↓のような感じです。
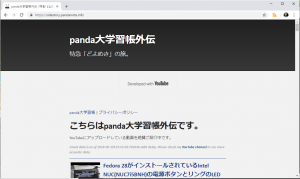
[2019/02/19 追記] Youtubeのチャンネル紹介のページをこちらに変更しました。
まとめ
ロゴを使った本記事で書いたシステムの概念図を書いて掲載する予定でしたが、YouTubeのロゴは利用条件が意外に厳しい(特に背景が無地の場合にはロゴの周囲に十分にスペースをとることとされています)ために、ロゴのレイアウトが難しくなりそうだったので、断念しました。
その分、文章による説明が増えてしまい、回りくどい書き方が他の記事よりも多くなってしまっているかもしれませんが、その点についてはあしからずご了承願います。
PCで動画をYouTubeにアップロードしようとするとコメントなどを入力することができる入力フィールドが現れ、コメントを入力できます。しかしながら、このコメントを一覧形式で確認することができなかったので、動画を管理する視点から見ても有益なページに仕上がったものと固く信じております。
…そのおかげで、コメントに何ヶ所か誤りが見つかりましたので、修正していきます。(´・ω・`)
この記事は以上です。
 【コード例を更新しました。】google-api-python-clientとPython3でちょっと遊んでみる。
【コード例を更新しました。】google-api-python-clientとPython3でちょっと遊んでみる。  Twitter APIでGitHub Pagesの更新情報を投稿するためのPython3のプログラムを書いてみた。
Twitter APIでGitHub Pagesの更新情報を投稿するためのPython3のプログラムを書いてみた。  YouTubeの収益化条件が厳格化されたので、本サイトにYouTubeのチャンネル登録のボタンを追加してみた。
YouTubeの収益化条件が厳格化されたので、本サイトにYouTubeのチャンネル登録のボタンを追加してみた。