はじめに
ちょいと野暮用に使おうと思い、Apache Solr 8.5.2(※この記事を最初に書いた時点(2020年6月)における最新版です。)に最新のNEologdを組み込むためのパッチを作成しました(動作は未確認ですが、ここ(GitHub)に置いてあります。)。
…が、今回の野暮用は品詞分解ができて名詞が抽出できさえすればよいので、前回Apache Solr用のパッチを作った時ほど大掛かりな準備を必要としなさそうなことにパッチを作った後に気が付いてしまいました。
そこで、Apache Solr 8.5.2用に作ったパッチを使ってkuromoji本体に対して最新のNEologdを組み込むためのパッチを作成してkuromojiのみをビルドし、出来上がったJARファイルを開発予定のコードから呼び出す方法により使うことにしました。
この記事では最新のNEologdを組み込んだJARファイルができるまでの顛末について書きます。
作成したパッチ
作成したパッチは以下の2個です。
- kuromojiに対して適用するパッチ。
- GitHubから取得した最新のNEologdに対して適用するパッチ。
kuromojiに対して適用するパッチ
以下の通りです。GitHub Gistに置いてあります。
最新のNEologdに対して適用するパッチ
以下の通りです。GitHub Gistに置いてあります。
このパッチはビルドの実行中にGitHubから取得した最新のNEologdのコードに対して自動的に適用されます。
パッチの適用及びビルドの手順
事前に確認が必要な事項
パッチの適用及びビルドの作業を行ったFedora 32のPCにはmaven,Java及びMecabがすべてインストールされていましたが、インストールがされていない場合にはdnf等のコマンドを用いる等の方法でパッチの適用及びビルドの前にインストールしておきます。
確認が終わったらビルド。
パッチの適用及びビルドは以下の手順で行います。
- 上記2個のパッチを同じディレクトリに置きます。
- 手順1のディレクトリにkuromojiをGitHubのリポジトリからcloneします。
- 以下のコマンドを実行し、1個目のパッチを適用します。
$ cd kuromoji
$ patch -p1 < ../kuromoji-pom-20200521.patch - 以下のコマンドを実行します。
$ mvn install
- ビルドの途中でNEologdのソースコードをダウンロードしてから辞書をコンパイルするので、時間がかかる場合があります。そんなときにはドーナツ🍩でも食べながら待ちます。
今日は朝から #シレトコドーナツ です。
時節柄、ドーナツ1個ごとに袋に入れられて販売されてます。
クマゴロンはかわいいですが、一番最初に食べられる運命にあります。#lifeinyokohama pic.twitter.com/iH1xkDl46E— pandanote.info (@Pandanote_info) June 17, 2020
スポンサーリンク
- ビルドが完了すると、Mavenのローカルリポジトリのディレクトリ($HOME/.m2/repository)の下にJARファイルがインストールされます。
- Enjoy!!😎
試運転
前節でビルドしたJARファイルを使って試運転をしてみます。
テスト用のコード(このコードについては別途記事を書く予定です。)をScalaで書いてFAT JARファイルを作成して試してみたところ…
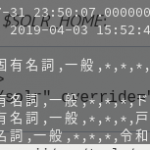
虎ノ門ヒルズ駅 名詞,固有名詞,一般,*,*,*,虎ノ門ヒルズ駅,トラノモンヒルズエキ,トラノモンヒルズエキ:false
で 助詞,格助詞,一般,*,*,*,で,デ,デ:false
下車 名詞,サ変接続,*,*,*,*,下車,ゲシャ,ゲシャ:false
し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ:false
て 助詞,接続助詞,*,*,*,*,て,テ,テ:false
新橋駅 名詞,固有名詞,一般,*,*,*,新橋駅,シンキョウエキ,シンキョウエキ:false
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ:false
向かい 動詞,自立,*,*,五段・ワ行促音便,連用形,向かう,ムカイ,ムカイ:false
ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス:false
。 記号,句点,*,*,*,*,。,。,。:false
「虎ノ門ヒルズ駅」が固有名詞として認識されているあたり、ただの辞書ではないなと考えざるを得ません。
問題点
NEologdを最新版に入れ替えてビルドを試みると、ビルド後のテストの際に一部の「の」の品詞が正しく判定されないために、以下のようなメッセージとともにテストが失敗します。
Failed tests: testNewBocchan(com.atilika.kuromoji.ipadic.neologd.TokenizerTest): expected:<助詞,[格助詞,一般],*,*,*,の,ノ,ノ> but was:<助詞,[連体化,*],*,*,*,の,ノ,ノ>
「テストの失敗箇所が1ヵ所であり、かつそれが助詞の部分であり、判定結果についても別の品詞と判定しているわけではないのでヨシ!! (AA略)」
ということで、ipadic-neologdのテストのうち、当該テストは上記パッチ適用後のビルド時のテスト対象から除外しています。
まとめ
kuromojiは使用する辞書ごとにJARファイルが分かれています。そこで、それらの間の比較を行うことために、前々節の試運転のために記述したコードは使用するJARファイルをコマンドラインオプションにより切り替えることができる仕様としています。
Javaで書けば比較的簡単に書けるコードであったのですが、Scalaで書いてみたところ、かなり大掛かりなコードになってしまいました(参考になりそうな文献もそれほどありませんでした)。
試運転のために記述したコードについては次の記事で書きましたので、見て行っていただけると幸いです。
この記事は以上です。
Related Posts / 関連ページ
 【追記しました。】Apache Solrを急遽始めました(2): DataImportHandlerの拡張用のコードをちょいと追加して、7-Zipで圧縮されたデータをインポートしてみた。
【追記しました。】Apache Solrを急遽始めました(2): DataImportHandlerの拡張用のコードをちょいと追加して、7-Zipで圧縮されたデータをインポートしてみた。
 Apache Solr 8用のNEologdを組み込んだkuromojiをビルドしようとしたところ、Apache Solr側の新元号対応が原因でハマった件。
Apache Solr 8用のNEologdを組み込んだkuromojiをビルドしようとしたところ、Apache Solr側の新元号対応が原因でハマった件。
 Apache Solrを急遽始めました(1): NEologdを組み込んだSolr7対応のkuromojiを作ってみた。
Apache Solrを急遽始めました(1): NEologdを組み込んだSolr7対応のkuromojiを作ってみた。
 Windows 10 Homeでsbt-assemblyを使ってFat JARファイルを作ったところ、パスの文字列長が長すぎてクラスファイルが不足していて実行できなかった件。
Windows 10 Homeでsbt-assemblyを使ってFat JARファイルを作ったところ、パスの文字列長が長すぎてクラスファイルが不足していて実行できなかった件。