はじめに
前の記事で、NEologdの入っているkuromojiを組み込んてみましたので、次の関門に挑みたいと思います。
実は、インデックスを行う対象となるデータセットが7-zipで圧縮されておりまして、これがよんどころない事情により展開して使うのが難しいため、Apache Solrにはできればシェルのコマンドプロンプトから
と実行後にPostToolを使ってデータをインポートをすることなく、7-zipで圧縮された状態のままDataImportHandlerへの入力として与えたいわけです。
…という感じでやりたいことを整理してから、Apache Solr(7.4.0)のソースコードを確認してみると、DataImportHandler経由のファイルのインポートは非圧縮のもののみがサポートされていることがわかりました。
そこで、DataImportHandlerで7-zipで圧縮されたファイルのインポートをサポートするコードを実装してから、DataImportHandlerの設定を行い、さらにその動作確認までを行いました。
この記事では上記の作業の流れについて書いていきます。
7-zipサポートの実装。
7-Zipサポートを実装するためには、以下のクラスが必要です。
- 7-Zipで圧縮したファイルを読み込むための入力ストリーム(InputStream)。
- 上記の入力ストリームを利用するためのデータソース(DataSource)。
上記の実装についてはScalaでいきなり書けるとかっこよさそうな感じがしないでもないのですけど、Apache Solrに組み込んだ上での動作の確認を優先したいので、とりあえずJavaで実装してからScalaへの移植を試みることにしました(Scalaへの移植ができた場合には、この記事を更新します)。
7-zip用InputStreamの実装例。
7-zip用InputStreamの実装例として、SevenZFileInputStreamクラスを定義し、以下のコード例のように実装しました。これはInputStreamクラスを拡張したもので、ファイルから読み込んだ(圧縮済の)データをクラス内部でcommons-compressに含まれているSevenZFileクラスに渡して展開しています。実は元ネタはScalaで書いていたので、結果的にはScalaからJavaに移植することとなりました。
7-zipをサポートするDataSourceの実装例。
7-zipをサポートするDataSourceの実装例として、SevenZFileDataSourceクラスを定義し、以下のコード例のように実装しました。これはApache SolrのDataImportHandlerに同梱されているFileDataSourceクラスを拡張したもので、読み込んだファイルの拡張子によって以下のように動作が切り替わります。
- 読み込んだファイルの拡張子が”7z”であった場合に限り、前節で定義したSevenZFileInputStreamクラスを使って入力ストリームを作成します。
- 1.以外の場合には拡張元であるFileDataSourceクラスと同じ動作となります。
JARファイルのビルド
上記の2個のクラスをまとめたプロジェクトを作成し、JARファイルをビルドします。
なお、作成したプロジェクトはGitHubに置きました。以下のURLで取得できます。
スポンサーリンク
https://github.com/pandanote-info/SevenZDataImporter
ここでも、ヘタレてできるだけ早く確実に動作させることを優先し、Eclipse+Mavenの組み合わせでビルド環境を構築し、ビルドすることとしました。
ビルドが終わったら、できあがったJARファイルをDataImportHandlerがあるディレクトリと同じディレクトリにコピーしておきます。
DataImportHandler及び関連した設定。
7-zipのサポート用のJARファイルを追加したら、次はDataImportHandler本体の設定とJARファイル読み込みのためのApache Solrの設定ファイル(solrconfig.xml)の記述を行います。
DataImportHandler本体の設定。
以下のように設定ファイル(dih-config.xml)を記述します。
注意が必要な点は以下の通りです。
- dataSourceタグのtype属性には、今回作成したDataSourceの拡張クラス(SevenZFileDataSourceクラス)をパッケージ名も含めて指定します。
- インポートの対象となるデータはサーバ側のリソースとして読み込むこととし、データの置き場所(本記事の設定では7-zipで圧縮されているファイルがあるディレクトリ)はApache Solrのインストール先のディレクトリ(solr.install.dirプロパティにセットされています。)からの相対パスで指定しています。
記述が終わったら、dih-config.xmlファイルをインポートしたいコアのインスタンスが作成されているディレクトリのconfの下に置きます。
solrconfig.xmlの設定。
前項で設定したdih-config.xmlファイルを読み込むための設定をインポートしたいコアのsolrconfig.xmlに追記します。追記した設定は以下の通りです。
上記の設定をsolrconfig.xmlのconfigタグの内側に記述します。
試運転してみた。
DataImportHandlerの試運転。
試しに日本語版Wikipediaのダンプファイルから必要そうなデータを取り出して、作成したコアにインポートしてみました。
DataHandlerを用いてインポートを行うためには、以下のコマンドを実行します。
{
“responseHeader”:{
“status”:0,
“QTime”:52},
“initArgs”:[
“defaults”,[
“config”,”dih-config.xml”]],
“command”:”full-import”,
“status”:”idle”,
“importResponse”:””,
“statusMessages”:{}}
インポートの途中経過を調べるためには以下のコマンドを実行するのですが…
インポートが終了するまでの間は、以下のような感じのレスポンスが返されます。
{
“responseHeader”:{
“status”:0,
“QTime”:0},
“initArgs”:[
“defaults”,[
“config”,”dih-config.xml”]],
“command”:”status”,
“status”:”busy”,
“importResponse”:”A command is still running…”,
“statusMessages”:{
“Time Elapsed”:”0:0:26.222″,
“Total Requests made to DataSource”:”0″,
“Total Rows Fetched”:”2600″,
“Total Documents Processed”:”2598″,
“Total Documents Skipped”:”0″,
“Full Dump Started”:”2018-08-04 14:27:15″}}
インポートが終了すると、以下のような結果が返されます。
{
“responseHeader”:{
“status”:0,
“QTime”:3},
“initArgs”:[
“defaults”,[
“config”,”dih-config.xml”]],
“command”:”status”,
“status”:”idle”,
“importResponse”:””,
“statusMessages”:{
“Total Requests made to DataSource”:”0″,
“Total Rows Fetched”:”2343194″,
“Total Documents Processed”:”2343148″,
“Total Documents Skipped”:”0″,
“Full Dump Started”:”2018-08-04 14:27:15″,
“”:”Indexing completed. Added/Updated: 2343148 documents. Deleted 0 documents.”,
“Committed”:”2018-08-04 16:53:45″,
“Time taken”:”2:26:29.709″}}
“Total Rows Fetched”と”Total Documents Processed”の数に差があるのがちょっと気にはなりますが、この差分と今回使用した日本語版のWikipediaのダンプファイルの個数が(たまたまかもしれませんが)一致するので、そういうものが一緒くたになってカウントされているんだろうなぁ…と何の根拠もなく推測してここではひとまず問題視しないことにします。
上記のインポートの実行時に’commit=true’をクエリ文字列に指定しているのですが、Apache SolrのAdmin画面の”Overview”の”Statistics”の”Current”の項目が”false”のままで変化しなかったので、以下のコマンドを実行します。
{
“responseHeader”:{
“status”:0,
“QTime”:735}}
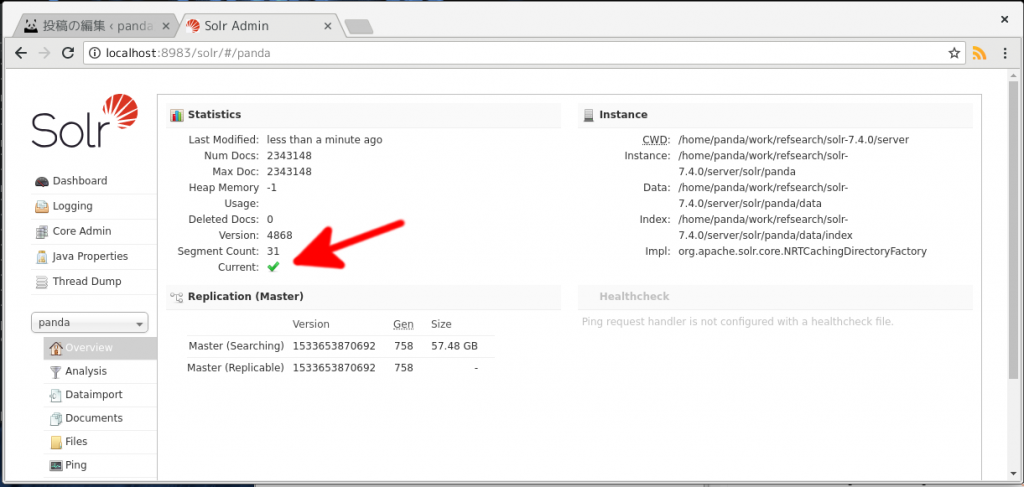
すると、Apache SolrのAdmin画面の”Overview”の”Statistics”の”Current”の項目が”true”に変化します(下図の赤矢印)。
検索の試運転。
試しにApache SolrのAdmin画面の”Query”で、「白金高輪駅」をキーワードとして検索してみます。
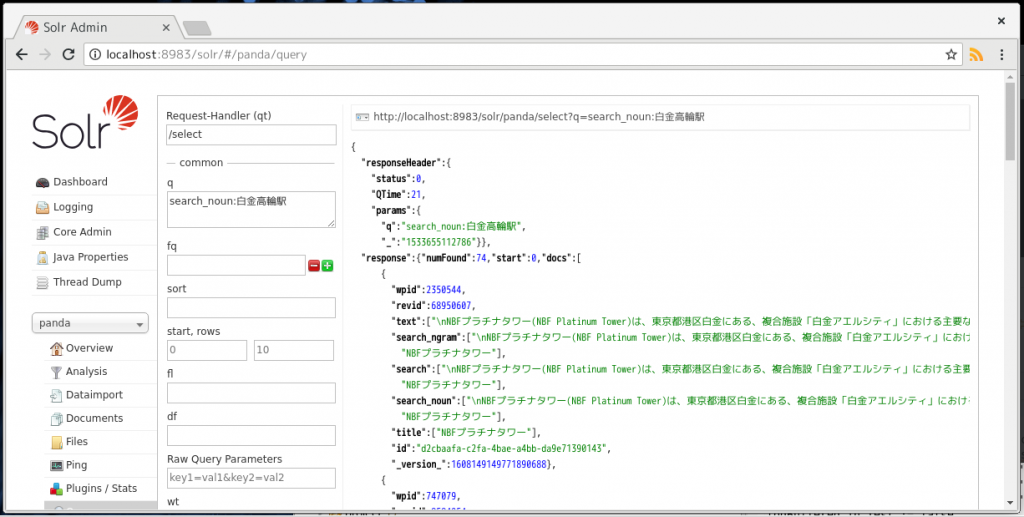
検索結果の先頭に白金高輪駅とは一見なんの関係もなさそうな建物が登場していますが、この建物は白金高輪駅直結の再開発エリアの一角に建っているビルです。また、上図では表示されていませんが、この記事の後ろの方に「白金高輪駅」の文字列が登場しています。よって、検索エンジン用のインデックスは正常に生成できているものと判断できます。
まとめ
この記事では、DataImportHandlerとその拡張例について書きました。
今回の拡張用のコードは確実に動作させることを優先させたために、最近推しているScalaではなくJavaで記述してしまいましたが、折を見てScalaに書き換える予定です。
この記事は以上です。
pom.xmlの変更[2019/10/22追記]
commons-compressに脆弱性が見つかったとのことなので、pom.xmlの記述を変更しました。
 Apache Solrを急遽始めました(1): NEologdを組み込んだSolr7対応のkuromojiを作ってみた。
Apache Solrを急遽始めました(1): NEologdを組み込んだSolr7対応のkuromojiを作ってみた。  Apache Solr 8用のNEologdを組み込んだkuromojiをビルドしようとしたところ、Apache Solr側の新元号対応が原因でハマった件。
Apache Solr 8用のNEologdを組み込んだkuromojiをビルドしようとしたところ、Apache Solr側の新元号対応が原因でハマった件。  Apache Solr 8用のkuromoji(NEologd入り)の動作確認のためにテキストファイルを1個だけインポートしてみた。
Apache Solr 8用のkuromoji(NEologd入り)の動作確認のためにテキストファイルを1個だけインポートしてみた。  JavaのリストをScalaのリストに変換しようとしたところ、割と盛大にハマったのでメモ。
JavaのリストをScalaのリストに変換しようとしたところ、割と盛大にハマったのでメモ。