はじめに
前の記事でNEologdを組み込んだkuromoji(以下、単に「kuromoji」と書きます。)のApache Solr 8用のjarファイルをビルドしてデプロイしたところまでを書きました。
Apache Solr 7への組み込み用のkuromojiのビルド及びデプロイを行ったときには日本語版Wikipediaのダンプファイルを使って動作確認を行いましたが、手元にある日本語版Wikipediaのダンプファイルが2018年現在のもので少々古く、かと言って新しいものをダウンロードするのも少々手間がかかることから、今回はApache Solr 8に対する設定は必要最低限のものとし、テキストファイルを1個だけ用意してそれをインポートすることで動作確認を行うという方法を採ることとしました。
この記事ではその方法について書きます。
データのインポート
…の前に、実行環境のダウンロード及びインストール
実行環境のダウンロード及びインストールは、以下の手順で行います。
- Apache Solrのダウンロードのページから”Binary releases”にあるファイルをダウンロードします。この記事を最初に書いた時点(2019年6月)ではVersion 8.1.1のものが置いてありましたので、ZIPファイル(solr-8.1.1.zip)をダウンロードします。以下、この記事ではsolr-8.1.1.zipをダウンロードしたものとして書きます。
- シェルのコマンドプロンプトで以下のコマンドを実行し、手順1でダウンロードしたZIPファイルを適当なディレクトリ上で展開します。
$ unzip solr-8.1.1.zip
- “solr-8.1.1″という名前のディレクトリが作成されたら、インストール完了です。
kuromojiのjarファイルのApache Solr 8の実行環境へのデプロイ
kuromojiのjarファイルのApache Solr 8の実行環境へのデプロイは、以下の手順で行います。
- kuromojiのjarファイルをApache SolrのWebアプリケーションがデプロイされているディレクトリのWEB-INF/lib(前項のsolr-8.1.1という名前のディレクトリからの相対パスで表現すると、solr-8.1.1/server/solr-webapp/webapp/WEB-INF/libになります。)の下にコピーします。なお、Apache Solrのデプロイ時と同じ権限であればroot権限でなくても構いません。
- 手順2のコピー先のディレクトリにはNEologdが組み込まれていないkuromojiがありますので、シェルのコマンドプロンプトから以下のコマンドを実行し、これを削除します。
$ rm lucene-analyzers-kuromoji-8.1.1.jar
動作確認のために用意したテキストデータ
以下のテキストデータを動作確認のために用意しました。
相鉄(相模鉄道)とJR東日本の直通線は令和元年11月30日に開業です。また、東急線との直通線は令和4年頃開業の予定です。
この記事を最初に書いた時点(2019年6月)において、横浜市民の間ではもっともホットな話題です。(`・ω・´)シャキーン
上記の文書をsampletext.txtというファイル名で保存しておきます。
Apache Solr 8の起動
シェルのコマンドプロンプトでcdコマンド等を駆使してカレントディレクトリを上記のsolr-8.1.1のあるディレクトリに移動後、さらに、
$ ./bin/solr start
と入力してEnterキーを押すと…
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=5891). Happy searching!
スポンサーリンク
と表示されて、Apache Solrが起動します。
なお、Warningについてはこの記事では気にしないことにします。
コアの作成
前節に続けて、Apache Solrにおいてインデクシング用のデータを格納する単位であるコアを作成します。
この記事では”panda”という名前のコアを作成してみます。
シェルのコマンドプロンプトで、
と入力してEnterキーを押すと…
To turn off: bin/solr config -c panda -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created new core ‘panda’
と表示されて、コアが作成されます。
なお、表示されているWarningについては気にしないことにします。
REST APIを用いたカスタマイズ
Apache Solrの起動ができたら、次はコアのschema(データの仕様のようなものです。)をカスタマイズし、Apache Solrによる動作確認(後述)時にインポートしたデータの中身の確認ができるように設定します。
コアのschemaのカスタマイズはcURLを使ってREST APIを発行してJSONのデータを送信することで行いますが、JSONのデータをシェルのコマンドプロンプトで手入力するのはかなりの手間なので、以下のようなREST APIを連続して実行するためのシェルスクリプトを書いて実行します。
上記のシェルスクリプトにより以下の3個のREST APIを発行することができます。
- 9-43行目: “text_ja”というフィールドタイプを再定義するためのREST APIです。ICUNormalizer2CharFilterFactory(17行目,ドキュメントの英数字やカタカナの全角半角の表記揺れを統一するためのfilterです。)及びSynonymFilterFactory(24行目,類義語辞書を利用するためのfilterです。)を追加しています。
- 45-56行目: “text_ja”というフィールドタイプのフィールドとして”search”という名前の負フィールドを追加するためのREST APIです。追加される”search”フィールドには以下の設定を行っています(termVectors, termPositions及びtermOffsetsはお好みで設定します)。
- multiValued: 1個のドキュメント中に同一のフィールド名を持つ複数のタグがある場合に、それらをすべてindexingの対象とする場合にtrueを指定します。
- indexed: インデックスの作成及び検索の対象とする場合にtrueを指定します。
- required: 必須のフィールドに対してtrueを指定します。
- stored: 検索の結果にフィールドの値を含める場合にはtrueを指定します。
- termVectors: 検索語として指定した語のフィールド中における出現状況(位置、オフセット等)についての情報を表示する場合にはtrueを指定します。
- termPositions: 検索語として指定した語の(単語を単位とした)出現位置についての情報を表示する場合にはtrueを指定します。
- termOffsets: 検索語として指定した語の(文字を単位とした)出現位置についての情報を表示する場合にはtrueを指定します。
- 58-62行目: “_text_”という名前のフィールドに格納されたデータを”search”フィールドにコピーするための設定です。”_text_”はApache Solrの内部で使用されるフィールドのようで、テキストファイルを特別な設定を行わずにインポートするとテキストファイルの中身はこのフィールドに格納されるようです。ただ、そのままではindexing等は行われないようですので、”search”フィールドにコピーしてやります。”search”フィールドへデータがコピーされるときにindexing等の処理を行おうという寸法です。「”_text_”フィールドを直接変更すればいいじゃん。」とも思えるのですが、アンダースコアから始まるフィールドは内部的に使われるフィールドだから無理に触っちゃいけないよとうちのばっちゃが言ってたので、無理に触らないこととしました。
上記のファイルを”minimun_customize_sample.sh”というファイル名で保存して、第1引数にコア名を指定して以下のように入力してシェルのコマンドプロンプトから実行すると…
“responseHeader”:{
“status”:0,
“QTime”:145}}
{
“responseHeader”:{
“status”:0,
“QTime”:37}}
{
“responseHeader”:{
“status”:0,
“QTime”:28}}
のように、REST APIの実行結果を示すresponseHandlerが3個出力されます。それらのresponseHandlerにはそれぞれのREST APIの実行状況を示すstatusフィールドが含まれていますが、それらがすべて”0″であればカスタマイズは成功です。
いよいよインポート
本当のインポートはここからです。
PostToolを使ってちゃっちゃと実行します。すると…
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/panda/update…
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sampletext.txt (text/plain) to [base]/extract
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/panda/update…
Time spent: 0:00:01.734
のようにインポートされます。
Apache Solr 8に組み込んだkuromojiの動作確認
その1: ヒットするかどうかの確認。
Apache Solr 8に組み込んだkuromojiが動作しているとすると、「令和」という単語が含まれている文書がヒットするはずなので、管理画面を使って以下の手順で確認してみます。
- ブラウザを起動します。
- http://localhost:8983/solr/ にアクセスします。
- Core Selectorのプルダウンボタン(下図の赤矢印(a))を押すと、設定されているコア名の一覧が現れますので、コア名を指定します。この記事では”panda”(下図の赤矢印(b))を指定します。
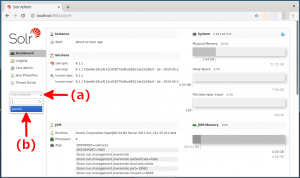
- Overviewの画面に切り替わりますので、画面左側のメニュー領域にある”Query”(下図の赤矢印)をクリックします。
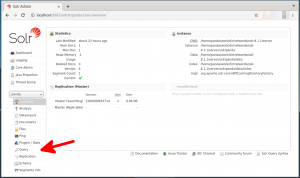
- Queryの入力画面に切り替わりますので、”q”のフィールドに”search:令和”と入力します(下図の赤矢印)。
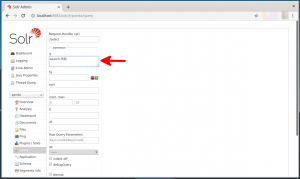
- 画面の下部にある”Execute”ボタンをクリックします。
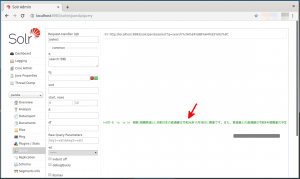
- 検索結果が1件表示されます。なお、表示するように指定した”search”フィールドも表示されていることを確認します(下図の赤矢印)。
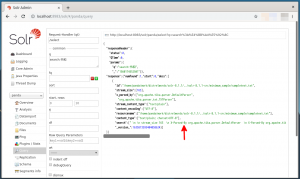
- 上図の検索結果は横にスクロールできますので横にスクロールしてみると、”search”フィールドに格納されているインポートした文書が表示されます(下図の赤矢印)。
その2: indexing時及び検索語の解析時の語句の解析状況の確認。
次に「令和」という単語が分解されずに一つの単語としてindexingされていることと、検索語として指定されたときに一語として解釈されることを確認します。
前節の手順に引き続き、以下の手順を実行すると確認できます。
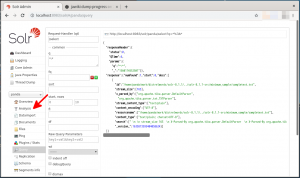
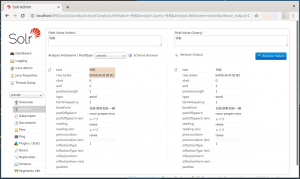
- 画面左側のメニュー領域にある”Analysis”(下図の赤矢印)をクリックします。
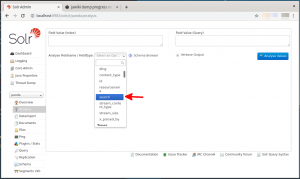
- 下図のように画面が切り替わりますので、”Analyse Fieldname / FieldType”のプルダウンボタンをクリックして”search”を指定します(下図の赤矢印)。
- “Field Value(index)”及び”Field Value(query)”のフィールド(下図の赤矢印(a)及び(b))に「令和」と入力し、”Analyse Values”ボタン(下図の赤矢印(c))をクリックします。
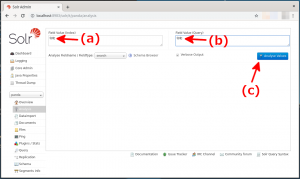
- 語句の解析結果が表示されます。「令和」が分割されていないのが確認できます。😎
まとめ
Apache Solrの動作確認のための必要最低限の設定の方法についてはあまりこれといった定番の方法が見当たらなかったことと、PDFやWordやCSVファイルでない「ガチの」テキストファイルをインポートした事例もなさそうだったので、理解できた範囲で少し詳し目に書いてみました。ご参考にしていただけると幸いです。🐼
この記事は以上です。
 Apache Solrを急遽始めました(1): NEologdを組み込んだSolr7対応のkuromojiを作ってみた。
Apache Solrを急遽始めました(1): NEologdを組み込んだSolr7対応のkuromojiを作ってみた。  【追記しました。】Apache Solrを急遽始めました(2): DataImportHandlerの拡張用のコードをちょいと追加して、7-Zipで圧縮されたデータをインポートしてみた。
【追記しました。】Apache Solrを急遽始めました(2): DataImportHandlerの拡張用のコードをちょいと追加して、7-Zipで圧縮されたデータをインポートしてみた。  Intel NUCのファイルシステムをbtrfsからXFSに変えたので、XFSのファイルシステムを作成する手順をメモ書きしてみた。
Intel NUCのファイルシステムをbtrfsからXFSに変えたので、XFSのファイルシステムを作成する手順をメモ書きしてみた。  xrdp+GNOME desktopのインストールとセットアップ on Fedora 27 Server
xrdp+GNOME desktopのインストールとセットアップ on Fedora 27 Server