はじめに
Twitterのタイムラインを眺めていたところ、
「最近のC++はプログラムの文字コードをUTF-8に設定して書くと、識別子に日本語が使える。」
という情報が流れてきたので、試してみることにしました。
環境
以下の環境で試してみました。
- OS: Linux (Fedora 36)
- C library: GNU Libc 2.35
- Compiler: GCC-12.1.1
試してみた
まずは簡単に変数名から…
以下のプログラムを作成し、”横浜線0.cpp”というファイル名で保存します。
#include <iostream>
#include <string>
int main(int 引数の数, char **引数) {
string 横浜線の起点 = “東神奈川”;
cout << 横浜線の起点 << endl;
}
コマンドラインの引数の部分もargc, argvではなく日本語の変数名にしてみました。
ファイル名の拡張子以外の部分にいきなりシングルバイトの文字列が混ざっていますが、それは気にしないことにします。
コンパイルして実行してみます。
すると…
g++ -c -o 横浜線0.o 横浜線0.cpp
g++ -o 横浜線0 横浜線0.o
[panda@pandanote.info 横浜線]$ ./横浜線0
東神奈川
のように出力されます。
横浜線の起点は東神奈川駅であることがわかります。
混ぜても安全
スポンサーリンク
次は変数名にシングルバイトの文字列と混ぜたものを使ってみます。
以下のプログラムを作成し、”横浜線の起点から31km.cpp”というファイル名で保存します。
#include <iostream>
#include <string>
int main(int 引数の数, char **引数) {
string 横浜線の起点から31km = “相模原”;
cout << 横浜線の起点から31km << endl;
}
コンパイルして実行してみます。
すると…
g++ -c -o 横浜線の起点から31km.o 横浜線の起点から31km.cpp
g++ -o 横浜線の起点から31km 横浜線の起点から31km.o
[panda@pandanote.info 横浜線]$ ./横浜線の起点から31km
相模原
という出力結果が得られます。
横浜線の起点(=東神奈川駅)から31kmのところには相模原駅があることがわかります。
全部入り
識別子として日本語の文字列が使えるということは、変数だけではなくて、構造体やクラスの型も日本語で表すことができそうです。
そこで、以下のプログラムを作成し、”横浜線.cpp”というファイル名で保存します。
#include <iostream>
#include <string>
#include <vector>
typedef struct {
int 乗降客数;
string 駅名;
} 駅の情報;
class 路線の情報 {
public:
string 路線名;
string 起点;
string 終点;
};
ostream &operator<<(ostream &out, const 路線の情報 &情報) {
return out << 情報.路線名 << “:” << 情報.起点 << “-” << 情報.終点;
}
int main(int 引数の数, char **引数) {
vector<駅の情報> 横浜線の駅;
駅の情報 鴨居;
鴨居.駅名 = “鴨居駅”;
鴨居.乗降客数 = 29426;
駅の情報 小机;
小机.駅名 = “小机駅”;
小机.乗降客数 = 7773;
駅の情報 新横浜;
新横浜.駅名 = “新横浜駅”;
新横浜.乗降客数 = 41089;
横浜線の駅.push_back(鴨居);
横浜線の駅.push_back(小机);
横浜線の駅.push_back(新横浜);
for (vector<駅の情報>::iterator 変数 = 横浜線の駅.begin();
変数 != 横浜線の駅.end();
++変数) {
cout << (*変数).駅名 << “:” << (*変数).乗降客数 << endl;
}
路線の情報 横浜線の情報;
横浜線の情報.路線名 = “横浜線”;
横浜線の情報.起点 = “東神奈川”;
横浜線の情報.終点 = “八王子”;
cout << 横浜線の情報 << endl;
}
さらにコンパイルして実行してみます。
g++ -c -o 横浜線.o 横浜線.cpp
g++ -o 横浜線 横浜線.o
[panda@pandanote.info 横浜線]$ ./横浜線
鴨居駅:29426
小机駅:7773
新横浜駅:41089
横浜線:東神奈川-八王子
鴨居、小机及び新横浜駅の駅名ならびに2020年の各駅ごとの乗降客数と横浜線の起点と終点が表示されました。
GitHubに置いてみた
前節までに作成したサンプルコードに加えてMakefileを作成しGitHubに置いてみました。
GitHubに置くためにはリポジトリの作成後にそのリポジトリをcloneしてローカルのリポジトリを作成し、作成したローカルのリポジトリに対して前節までに作成したサンプルコード及びMakefileを追加するという作業を行う必要があります。
実際にFedora36上のコマンドプロンプトからgit add及びgit commitコマンドを実行してみると…
[panda@pandanote.info identifier-in-japanese]$ git commit . -m ‘ * Add some codes.’
[main 0fbe737] * Add some codes.
3 files changed, 80 insertions(+)
create mode 100644 “\346\250\252\346\265\234\347\267\232.cpp”
create mode 100644 “\346\250\252\346\265\234\347\267\2320.cpp”
create mode 100644 “\346\250\252\346\265\234\347\267\232\343\201\256\350\265\267\347\202\271\343\201\213\343\202\21131km.cpp”
のように出力されます。
表示上はものの見事に文字化けします。
文字化けは単に出力表示上の問題であろうと信じつつ、git pushを実行し、GitHubのリポジトリのページにアクセスします。
すると…
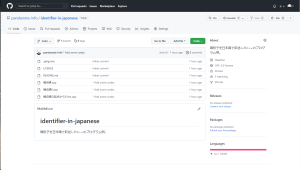
GitHubのリポジトリにサンプルコードとMakefileが反映されていることが確認できました!!
なお、GitHubのリポジトリ名に日本語の文字列を使うことはこの記事を最初に書いた時点(2022年6月)ではできないようです。
残念。
考察
日本語で変数名を書きたいがマルチバイトの文字列を使いたくないときに我が国のIT業界でよく使われる「常識的」な手法としてはローマ字に変換するという方法があります。
しかし、その変換方法には大きく訓令式とヘボン式の2通りがあります。
2通りの方式が存在する時点で考え方にズレが生じそうな予感がしますが、鉄オタ的な視点から考えるとどうしても↓の例のようなヘボン式の表示法に肩入れしたくなります。
400年ぶりくらいに #町田駅 にやってきました。#lifeinyokohama pic.twitter.com/Ib2sofcyF2
— pandanote.info (@Pandanote_info) April 9, 2022
訓令式の場合、「町田」のローマ字表記は”Matida”になります。
本Webサイトの管理人たるpandaがソフトウェアやデータベースの設計をするときには、変数、クラス名、テーブル名、カラム名等の(日本語で記述された)論理名(以下、単に「論理名」と書きます。)を物理名に変換する場合には、
- 英語に変換できるのであればできるだけ英語に変換。
- 英語への変換が無理ならヘボン式でローマ字に変換。
という変換ルールで変換を行っています。しかし、変換された英語の意味や綴りが理解できないと1のルールは使えません。
上記の1のルールが使えない状況下で、設計に関与しないソフトウェアやデータベースの設計時に論理名→物理名の変換を訓令式で行う人が現れると…
かなりストレスになります。間違いの原因になったりもしますが、原因がローマ字変換された日本語の書き間違いということになるので、日本語ネイティブかつ「ローマ字といえばヘボン式ですよね。」と信じて疑わない人にとってはかなりストレスフルです。
そんなときに、論理名を直接物理名としてプログラムに書くことができれば少なくとも日本語の単語のローマ字への変換方式に起因する誤りは発生しなくなるものと考えられます。
一方で、プログラム中のコメント以外の部分で日本語を実際に書いてみる意外に日本語変換で手間取り、ストレスを感じることがあります。
このストレス感は識別子を日本語で表記することの短所と言うことができそうです。
まとめ
C++のプログラムだけではなく、Makefileも日本語表示に対応していたのは予想外だったので、勢いでプロジェクトのようなものを作成し、GitHubにプログラムを置いてみることにしました。
ご参考にしていただけると幸いです。
この記事は以上です。
 【追記しました。】Apache Solrを急遽始めました(2): DataImportHandlerの拡張用のコードをちょいと追加して、7-Zipで圧縮されたデータをインポートしてみた。
【追記しました。】Apache Solrを急遽始めました(2): DataImportHandlerの拡張用のコードをちょいと追加して、7-Zipで圧縮されたデータをインポートしてみた。  Fedora 24から25へのアップグレード
Fedora 24から25へのアップグレード  【バージョンを変更しました。】SikuliX-2.0.1をインストールして、GIMP-2.10でよく使う操作を自動化してみた。
【バージョンを変更しました。】SikuliX-2.0.1をインストールして、GIMP-2.10でよく使う操作を自動化してみた。  Fedora 33から34へのupgrade
Fedora 33から34へのupgrade