はじめに
2022年7月あたりから急に流行りだした画像生成AIの世界ですが、ローカル環境で動かすことができそうなもの(Stable Diffusion)がオープンソースになったとの情報を入手しました。
そこで、とりあえずNUC+Fedora36+Anaconda3の構成でローカル環境を構築して動作を確認するところまでこぎつけてみました。
しかし、anaconda3をインストールすることでシェルのコマンドプロンプトの表示内容を変えられてしまうことにかなり強い違和感を感じたので、anaconda3のかわりにpipを使ってStable Diffusionを稼働させるために必要なパッケージをインストールし、それを使ってStable Diffusionのローカル環境を構築してみることにしました。
事前準備
Stable Diffusionの学習データ(普通に1GBを超えます。)をGitHubからダウンロードする前に、以下のコマンドを実行してgit-lfsをインストールします。
git-lfsをインストールしておかないと、txt2img.pyの実行時に、
_pickle.unpicklingerror invalid load key ‘v’
などどいう謎のエラーに遭遇することになります。
また、pipを用いたdlibパッケージのインストールの際に使用しますので、cmakeも以下のコマンドを実行してインストールしておきます。
プログラム等のダウンロード及びセットアップ
ソースコード
Stable Diffusionの本家のmainブランチではこの記事を最初に書いた時点(2022年8月)ではCUDA経由でしか動かすことができないため、Apple SiliconのGPUのサポート用のコードが組み込まれている別のブランチからソースコードをチェックアウトします。
そこで、以下のコマンドを実行します。
$ cd stable-diffusion
$ git checkout apple-silicon-mps-support
すると、stable-diffusionディレクトリの下にApple SiliconのGPUサポートが組み込まれているソースコードがチェックアウトされます。
学習データの取得
スポンサーリンク
学習データの取得は、以下の手順で行います。
- huggingface.coに登録し、ユーザID及びパスワードを取得します。
- 以下のコマンドを実行します。
$ git clone https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
- ユーザID及びパスワードはhuggingface.coに登録したものを2回入力します。
- 2回目のcloneで学習データがダウンロードされるが、stable-diffusion-v-1-4-originalの場合は4GBくらいあってそれなりに時間がかかるので、コーヒー☕でも飲みながら待つこと。
シンボリックリンクの設定
以下のコマンドを実行します。
$ ln -s ../../../stable-diffusion-v-1-4-original stable-diffusion-v1
$ cd stable-diffusion-v1
$ ln -s sd-v1-4.ckpt model.ckpt
pipを用いたパッケージのインストール
インストールの手順
インストールの手順は以下の通りです。
- PyTorchのWebサイトにアクセスします。
- 「INSTALL PYTORCH」のセクションのボタンを(下図の赤矢印(a))のようにクリックします。
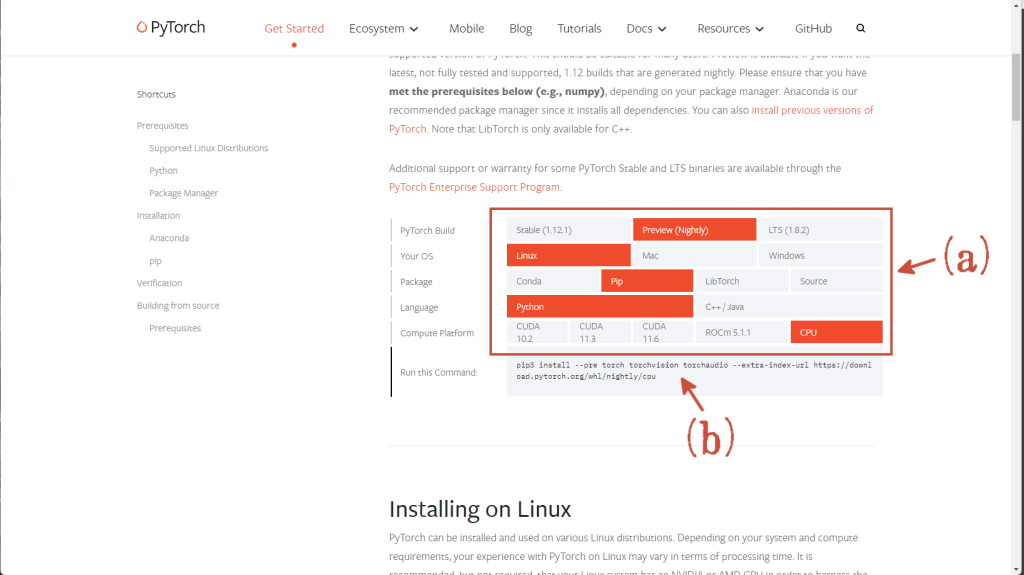
- 上図の赤矢印(b)にPyTorchのインストール用のコマンドが現れますので、実行します。なお、「pip3」とあるのは「pip」に読み替えて実行します。
$ pip install –pre torch torchvision torchaudio –extra-index-url https://download.pytorch.org/nightly/cpu
- 以下のコマンドをひたすら実行します。
$ pip install –upgrade pip
$ pip install –upgrade numpy
$ pip install opencv-python
$ pip install omegaconf
$ pip install tqdm
$ pip install invisible-watermark
$ pip install einops
$ pip install pytorch-lightning
$ pip install dlib
$ pip install skimage
$ pip install scikit-image
$ pip install ai_tools - ai_tools/microsoft_demo.pyの74行目を以下のように修正します。
print cl
↓
print(cl)スポンサーリンク - 以下のコマンドをひたすら実行します。
$ pip install cognitive_face
$ pip install zprint
$ pip install test-tube
$ pip install streamlit
$ pip install albumentations
$ pip install torch-fidelity
$ pip install transformers
$ pip install torchmetrics
$ pip install kornia
$ pip install diffusers
$ pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
$ pip install -e git+https://github.com/openai/CLIP.git@main#egg=clip - $HOME/.bashrcに環境変数PYTHONPATHの設定を追加します。
export PYTHONPATH=”<カレントディレクトリ>:$PYTHONPATH”
注意事項
pipを使うとldmという名前のパッケージがあってインストールできますが、Stable Diffusionとは無関係のパッケージなので、誤ってインストールしてしまった場合には削除すること。
画像の生成
以下のコマンドを実行します。
2-3時間ほど待つと、promptオプションで指定した文字列に対応する画像が生成されます↓

「横浜の夜景」ということで作ってみましたが、どことなく横浜と香港を足して2で割ったような感じの画像が生成されました。
なお、”--precision full”オプションなしで実行すると、
expected scaler type BFloat16 but found Float
というエラーが出力されます。
まとめ
諸々の事情で動作確認に使用しているNUC(こちらのNUCになります。CPUはIntel(R) Core(TM) i5-7260Uでメモリは32GB積んでいます。)をanaconda3専用機というか、Stable Diffusion専用機として使用することが難しいので、anaconda3はアンインストールし、pipで構築する道を探ってみた次第です。
CUDAやApple SiliconのMPSが使えるともう少し処理時間を短縮できるのかもしれませんが、処理時間がかかることよりもanaconda3がコマンドプロンプトの表示や環境変数PATHの設定等を変更してしまうことに対しての方により違和感を持ってしまう方にはおすすめの構築方法になります。
この記事は以上です。
 OpenVPN設定外伝: 設定でハマったところn選
OpenVPN設定外伝: 設定でハマったところn選  Fedora 27で久々にSamba4を動かしてみた。
Fedora 27で久々にSamba4を動かしてみた。  【動画作りました。】Fedora 28がインストールされているIntel NUC(NUC7i5BNH)の電源ボタンとリングのLEDの色を変えることができるようになるまでの、ちょっと長めな道のり。
【動画作りました。】Fedora 28がインストールされているIntel NUC(NUC7i5BNH)の電源ボタンとリングのLEDの色を変えることができるようになるまでの、ちょっと長めな道のり。  変数名などの識別子を日本語表示にしたC++のデモプログラムをGitHubに置いてみた。
変数名などの識別子を日本語表示にしたC++のデモプログラムをGitHubに置いてみた。