はじめに
IPFSのノードを立ち上げたのは良いのですが…
IPFSのノードはかなりメモリを消費する(500MBくらい)ので…
- IPFSのプロセス(ipfs)がOOM Killerの標的にならないように設定する。
- 他のメモリを消費しそうなプロセスは別サーバに移動する。
等の策を講じ、さらにcronで週に3回くらいIPFSを再起動させることによりなんとかあまり止まることなく稼働するようにはなりました。
…などど報告しようと思った矢先にまたサーバ全体を巻き込んで止まってしまうという事態が頻発するようになってしまいました。
cronでの再起動を週に3回から1日1回に変更してもサーバ全体を巻き込んで止まってしまうという事態が起こらなくなる… ということはありませんでした。
そこで、IPFSのノードを安定稼働させようと試みているVPS(さくらのVPSです。)のスケールアップを行うことにしましたので、その顛末について書いていきます。
スケールアップに成功するまで
事前調査や状況確認のようなもの
IPFSのノードを安定稼働させようと試みているVPSは石狩リージョンの1Gプランなので、石狩リージョンの2Gのプランにスケールアップすることになります。
1Gプランと2Gプランの金額差は年額にして約8000円です(この記事を最初に書いた時点(2022年6月)の情報です)。
お財布に金額差が激しく突き刺さります。
とはいうものの、メモリ容量及びストレージ容量は2倍になる(CPUのコア数は1.5倍になりますが、ここでは考えないことにします。)にもかかわらず、価格差が2倍を下回っている…と考えればコスパは悪くないようにも見えます。
そこで、スケールアップボタンをポチることにしました。
実際にポチる前にスケールアップ前の状況を確認します。
すると…
スポンサーリンク
( ゚д゚)
(つд⊂)ゴシゴシ
(;゚д゚)
(つд⊂)ゴシゴシ
, .
(;゚ Д゚) …?!
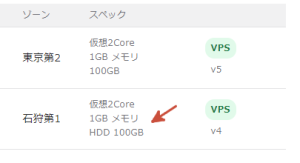
IPFSノードがHDDで動作していることが発覚しました(上図の赤矢印)。
これはいろいろとあやしそうです(単に忘れていただけですが)。
他におかしいところがないかと思い、VPSのリソース情報(今回初めて確認しました。)を確認しました。
すると…
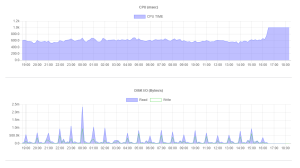
CPUタイムが1秒(=1000msec)で頭打ちになっていることを除けば、ディスクIOも含め特に問題はないように見えます。
スケールアップ作業概論
調査可能な部分については調べがついたと判断したところで、IPFSのノードが稼働しているサーバを停止し…
今度こそ「スケールアップ」ボタンをポチります。
ストレージはストレージ変更オプションを適用することにより2倍に増量(100GB→200GB)です。
スケールアップ作業自体は「さくらのVPS」でガイドされている方法[1]に従うことで、約15分程度で完了しました。
ストレージの増量対応で大変な目に遭った件
ストレージが増量されているため、パーティションテーブルを変更しました。
パーティションテーブルの変更はこの記事の「rootパーティションのサイズの拡大」に記載の方法で行いました…
が、しかし…
ストレージのもともとのパーティションテーブルがMBR対応のものであったため、上記の方法でrootパーティションのサイズを変更してその結果を保存するとパーティションテーブルがGPT対応のものに変わってしまうため、そのままではこのストレージからの起動ができなくなります。
かなりつらいです。
そこで、以下の手順でパーティションテーブルをMBR対応のものに戻します。
- FedoraのLive ISOをダウンロードします。
- 手順1でダウンロードしたLive ISOをさくらのVPSのコントロールパネルからアップロードします。
- このページ及びこのページの手順に従って、レスキューブートを行います。
- ブート後はインストールは行わず、Live ISOで起動します。
- Terminalを起動します。
- コマンドプロンプトから以下のコマンドを実行し、パーティションテーブルをMBR対応のものに戻します。
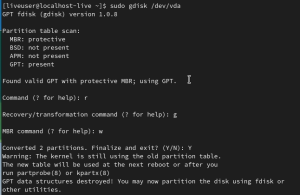
- 以下のコマンドを実行します(“fedora-root”の部分は設定の状況により読み替えます)。

- 以下のコマンドを実行し、GRUB2を再インストールします(パーティション名はストレージの状況により適宜読み替えます)。
$ /usr/bin/grub2-install /dev/vda
- 再起動します。
ここまでの作業でパーティションテーブルを変更することができます。
スケールアップ後
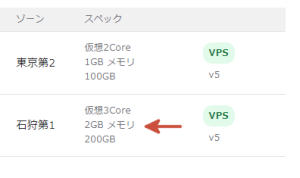
スケールアップが完了したことは、さくらのVPSのコントロールパネルより確認することができます(下図の赤矢印)。
VPSのリソース情報を確認してみます。
すると…
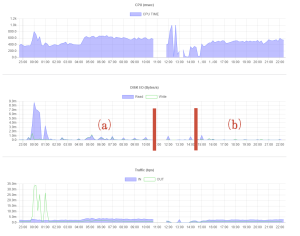
Disk I/Oのグラフの左側の赤色の縦棒から左の部分((a)の部分)がスケールアップ前のグラフで、右側の赤色の縦棒から右の部分((b)の部分)がスケールアップ後のグラフです。
スケールアップ後の方がReadによるDisk I/Oが少なくなっていることがわかります。
正確な原因はわからないですが、Read要求に失敗してリトライが発生している可能性がありそうです。
まとめ
スケールアップによって、CPUのコア数、ストレージの種類及び容量、メモリの容量が一度に変わってしまったために、IPFSのノードがサーバ全体を巻き込んで止まる原因が正確にはわからなくなってしまいました。
当初はメモリが少ないことを原因として疑っていましたが、前節の結果を見るとストレージがHDDであったことが一番の原因である可能性もありそうです。
仮に時々サーバ全体を巻き込んで止まる原因がHDDだったとすると、ストレージはSSDに変更された上に残りの容量にはかなり余裕があります。そこで、IPFSノード以外の用途に使用できそうだとは思わずに、当面はこのまま様子を見たいと考えています。
とにかく快適になったのでとりあえずヨシ!! ということにしておきたいと思います。(`・ω・´)
この記事は以上です。
 【コード例を更新しました。】google-api-python-clientとPython3でちょっと遊んでみる。
【コード例を更新しました。】google-api-python-clientとPython3でちょっと遊んでみる。  本サーバをこっそりFedora 26から27にアップグレードしてみたところ、不具合が出たので、修正した件。
本サーバをこっそりFedora 26から27にアップグレードしてみたところ、不具合が出たので、修正した件。  Annotation By Country プラグイン(1): 注釈型簡易多言語対応化WordPressプラグインを作ってみた。
Annotation By Country プラグイン(1): 注釈型簡易多言語対応化WordPressプラグインを作ってみた。  長めの記事が増えてきたので、Easy Table of Contentプラグインで目次を入れてみた。
長めの記事が増えてきたので、Easy Table of Contentプラグインで目次を入れてみた。