はじめに
前の記事でOAuth2認証後にGitHub APIを実行して追加のデータを取得する方法について書きました。
本Webサイトではコード例またはコード例のようなものをGitHub Gist(以下、単に「Gist」と書きます。)にアップロードし、scriptタグを使って貼り付けています。
ただ、scriptタグを使って貼り付けたGistのコード例またはコード例のようなものの数は記事の数にほぼ比例して増えていくことになります。この記事を最初に書いた時点(2019年3月)ではGistにアップロードしたコード例またはコード例のようなもの数は71個ありますが、そろそろ何をアップロードしたのかをすぐには思い出せない領域に入りつつあると感じています。
そこで、GitHub APIを使うとGistについての情報を取り出すことができることを利用して、Gistのコード例またはコード例のようなもののリストで、かつ一覧性に富むものを作ることにしましたので、この記事ではその顛末について書いていきます。
まず、仕様を決めます。
例によって、最初に仕様を決めます。
出力の表示方法。
出力の表示方法については最初は本Webサイト(panda大学習帳)のサイドバーのウィジェット形式で表示することを予定していて、広告枠を一部削除し、それによって捻出されるスペースに入れるつもりでした。
しかしながら、実は本Webサイトのサイドバーの広告枠は本Webサイトの管理人たるpandaの予想以上にご好評をいただいていることと、本文の記事の記事量とのバランスがとりにくくなる(=サイドバーの長さが調整しにくくなる)可能性があることから、本Webサイトへの追加は行わず、かわりに「panda大学習帳外伝」のページとして作成する方向に変えました。
markdown形式のファイルの作成。
「panda大学習帳外伝」のページはGitHub Pages側のJekyllっぽいサイトジェネレータによって作成されているものであり、その元ネタとしてmarkdown形式のファイルが必要です。つまり、Gistのリストファイルもmarkdown形式で生成する必要があります。
そこで、Gistのリストファイルもmarkdown形式で生成するPython3のプログラムを書くことにしました。
“private”なGistのファイルの取扱について
※本節の記述は本Webサイト及び「panda大学習帳外伝」のみにおける方針について記述したものであり、同様の方針を他のWebサイト等に対してお勧めするものではありません。
Gistのリストについての情報はGitHub APIを使ってGitHubから取得することになりますが、Gistにアップロードされているファイルのステータスが”private”に設定されているものがあり、それらをGistのリストファイルに含めるか否かについては決めておく必要があります。
なぜ”private”に設定されているものがあるのかというと、「よく考えないまま”private”に設定してしまったから」です。ただ、それらのGistについてもURLがわかると見ることができてしまうものであり、実際”private”に設定されているGistでも本Webサイトにscriptタグを用いて貼り付けられているものがあります。
本WebサイトのポリシーとしてはGistにアップロードしたファイルは(“private”に設定されているかどうかに関係なく)特に公開しても差し支えないものという認識ですので、今回作成する予定のGistのリストファイルには”private”に設定されているものも含めることにしました。
“private”なGistのファイルについての情報の取得
スポンサーリンク
“private”なGistのファイルについての情報を得るにはOAuth2認証を行いアクセストークンを取得する必要があります。
そこで、前の記事に書いた手順でOAuth2認証を行うことにより取得したアクセストークンを保存しておき、”private”なGistのファイルについての情報を得るために使用することにします。
前の記事のアクセストークン関連の部分をお読みいただくとなんとなくお察しかとは思いますが、この記事を最初に書いた時点(2019年3月)ではGitHub APIのアクセストークンには有効期限はなさそうに見えます。
有効期限がない点についてはそういうものなのだろうということで、気にしないことにします。😀
マッシュアップ? – Gistファイルが貼り付けられている記事へのリンク
前節までの検討で、Gistにアップロードしたファイルについての情報が取得できることがわかったので、これでファイルのリストをmarkdown形式で出力するプログラムが書ける…
…と思いPython3のプログラムを書いて試運転をしてみました。
でも、何かが足らないと感じました。
もともと、Gistにアップロードしたファイルは本Webサイトのどこかの記事に貼り付けるためにアップロードしているものです。それなら生成するファイルのリストに貼り付け先へのリンクを設定した方が便利なのではないかと思い、その方法を模索することにしました。
そして、以下の事実に着目しました。
- GistにアップロードしたファイルのGitHubにおけるURLにファイルを一意に識別するためのハッシュ値っぽい文字列(下図の赤矢印(a))が含まれていること。
- そのハッシュ値っぽい文字列が貼り付け用のscriptタグのURL(下図の赤矢印(b))にも含まれていること。
- 貼り付け用のscriptタグは本Webサイトの記事の一部になるため、本Webサイトが使用しているMariaDBのデータベースに格納されていること。
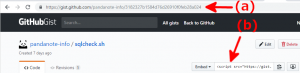
上記の事実を利用して、本Webサイトで使用しているデータベース(以下、単に「データベース」と書きます。)に格納されている記事をハッシュ値を用いて検索して貼り付け先の記事を探し出すことにしました。
というわけで、root権限で以下のコマンドを実行し、mysql-connector-pythonパッケージをインストールし、Python3からMariaDBにアクセスするための環境を整えました。
ちょっと前にWebアプリケーション界隈で流行った言葉で表現するならば、GitHub APIとMariaDBのマッシュアップ? ということになります。😎
その他、注意すべきこと。
- MariaDBへ接続することにしたので、接続に必要な情報は別ファイルから読み込むことにします。
- GitHub APIをOAuth2認証済みの状態で実行するためのアクセストークンも別ファイルから読み込むことにします。
- 上記2個のファイルはJSONフォーマットとし、Python3のプログラムを読むことで設定項目が理解できるように実装します。
- 他のSNS系のAPIなどと同様の仕様ではありますが、1回のAPI呼び出しで情報を得ることができるGistのファイルの個数に上限がある(詳細には調べていませんが、1回のAPI呼び出しで情報を得ることのできるGistのファイルの個数の上限のデフォルト値(API呼び出し時に指定しない場合。)は30のようです。)ようです。そこで、API呼び出し時にパラメータ(page及びper_page)を追加しつつAPIを数回に分けて呼び出すことにより、すべてのGistのファイルについての情報を呼び出すことができるように実装します。
コードを書きます。
出来上がったPython3のプログラムは以下のような感じになります。
MariaDBへの接続及びGitHub APIをOAuth2認証済みの状態の下での実行のために必要な設定はJSON形式で読み込む方式としています。
また、ハッシュ値っぽい文字列を使ってデータベースを検索する際にURLの一部になっているハッシュ値っぽい文字列だけを検索結果として取得できるようするために、検索に使用するSQL文のlike句の先頭にスラッシュを追加しています。
markdownファイルを生成してみます。
上記のコードで生成したmarkdownファイルの内容(1件分)は以下のような感じになります。
* Created at: 2019-02-03T21:43:59Z
* Updated at: 2019-02-04T12:24:20Z
* Descrption: Let’s encryptから取得した証明書を更新するためのコマンドを証明書が更新可能なタイミングでのみ更新するためのシェルスクリプト。
* [Link to Gist](https://gist.github.com/5572114fd1d89465051db798f64501ff)
* Referenced from:
* [Let’s encryptのドメイン認証の方法を証明書の更新にあわせてHTTP-01に変更してみた(おまけつき)。](https://pandanote.info/?p=3842)
時刻はGMT表示になります。
表示例。
作成したファイルをGitHub PagesにpushしてHTMLファイルを生成すると、以下のような感じでブラウザに表示されます。
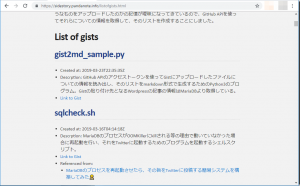
このファイルの全貌がこちらからアクセスできます(リストの途中に広告が表示されます。)。
GitHubから取得した情報にひと手間かけただけですが、割と見やすいものが作れたと思います。(`・ω・´)
まとめ
最初はGitHub APIだけを使ってGistのファイルリストを作る予定でしたが、それだと、GitHubで提供しているGistのファイルリストのページとの間の差分が見た目の相違くらいになってしまいます。そこで、
Wordpressのデータベースから関連する記事の情報を取得して、その記事へのリンクを生成する機能をmarkdown形式のファイルの生成プログラムに追加することで、機能での違いが出せるようにしてみました。
Gistにアップロードしたファイルに関連する記事へのリンクがあると、アップロードしたファイルの記事中における役割を容易に思い出すことができるようになるので、ファイルの適切な再利用や修正がやりやすくなると思います。
この記事は以上です。
 GitHub APIを使って、GitHub上の自分のリポジトリの一覧を表示する簡易なウィジェットを作ってみた。
GitHub APIを使って、GitHub上の自分のリポジトリの一覧を表示する簡易なウィジェットを作ってみた。  OAuth2による認証を行った後、GitHub APIを実行してみた。
OAuth2による認証を行った後、GitHub APIを実行してみた。 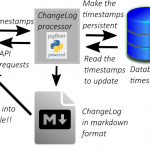 GitHub Pagesのトップページの記事一覧をMariaDBの力を借りて作成日時と最終更新日時(のようなもの)順に並べてみた。
GitHub Pagesのトップページの記事一覧をMariaDBの力を借りて作成日時と最終更新日時(のようなもの)順に並べてみた。  GitHub Pagesで構築したWebサイトのURLをAmazonアソシエイトに追加登録の申請をしたところ、3回目の申請で追加が承認された件。
GitHub Pagesで構築したWebサイトのURLをAmazonアソシエイトに追加登録の申請をしたところ、3回目の申請で追加が承認された件。