はじめに
すでにご案内の通り、本Webサイトのサブドメインである「panda大学習帳外伝」はGitHub Pagesを使って構築されています。
GitHub Pagesを使って構築できるWebサイトは基本的にはstaticなものであり、凝ったUIを持つものは構築することが難しかったりしますので、panda大学習帳外伝のトップページに載せている記事一覧も…
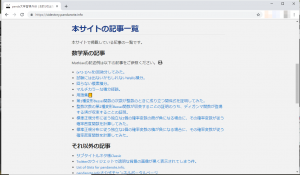
というような感じになっていて、どことなく未完成な雰囲気が漂います(※個人の感想です)。
そこで、この何とも言えない未完成感を払拭すべく、記事一覧に記事ごとの作成の日付及び最終の更新の日付を追加するためのPython3のプログラムを書いてみることにしました。
まず、仕様を考えます。
ざっくりとした仕様
GitHub Pagesの記事はGitHubのサイトにアップロードされているmarkdownファイルがHTMLファイルにコンパイルされたものが記事として公開されています。
しかし、GitHubはプログラム(またはそれに準ずるもの)がファイルとして置かれることが主に想定されているからかどうかわかりませんが、ファイルごとの作成日時や更新日時(のようなもの)をファイルに直接紐づくデータとしては保持していません。
そこで、ファイルごとの作成日時や更新日時(のようなもの)を得る方法を最初に考えます。
ファイルごとの作成日時や更新日時(のようなもの)は以下の手順で得ることができそうです。
- GitHub API(以下、この記事では単に「API」と書きます。)を使って、コミットのデータを取得する。
- コミットのデータから以下の項目を探し出し、取得する。
- コミットが行われた日時
- コミットの対象となったファイル
- 前項の日時をファイルごとに分類する。
- ファイルごとに分類された上記の日時のうち、もっとも早いものをファイルの作成日時、遅いものを最終更新日時とする。
上記の方法で得られたファイルの作成日時及び最終更新日時はあくまでも最初及び最後に当該のファイルがコミットされた日時であって、コミット後のGitHub側でのコンパイルが失敗してしまう等の理由によりファイルの作成日時及び最終更新日時とは厳密な意味でイコールではないですが、他にファイルの状態が変化した日時を知るためのGitHub APIが提供されていないことから、
ファイルの作成日時及び最終更新日時 = 最初及び最後に当該のファイルがコミットされた日時
とみなすこととしました。
GitHub APIを使用するが故に考慮が必要な事項。
アプリケーションの登録。
前項の手順でファイルの作成日時及び最終更新日時(のようなもの)を得ることはできます。しかしなから、それらを得るための情報はAPI経由での取得となることと、この類のAPIの例としてAPIの呼び出しの回数がAPIサービスの提供側で設定した値に到達すると、
![]()
…というような感じで怒られてしまいます。
幸いなことに、GitHub APIの場合には認証されたリクエストであればより多くの回数のリクエストを受け付けることができる旨のメッセージが(上記の通り)表示されていますので、アプリケーションの登録を行います。
なお、登録の方法についてはこちらをご参照ください。
APIの実行回数等の最適化。
スポンサーリンク
前項の方法で許容される最大のリクエスト回数を引き上げることができるものの、一度取得した情報を取得するために都度APIを発行し直すのは処理として冗長なものになってしまいます。
そこで、GitHub APIを通じて取得したファイルの作成日時及び最終更新日時(のようなもの)についての情報はいったんデータベースに格納し、次に記事一覧を作成する際にデータベースから上記の情報を読み出してGitHub API経由で読み出したコミットの情報を使って更新し、更新情報ファイル(markdownフォーマット)を作成後にファイルの作成日時及び最終更新日時(のようなもの)の更新後の情報を再度データベースへ格納する処理モデルを考えます(下図)。
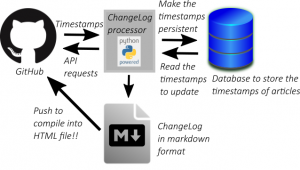
更新情報ファイルの作成の対象となるWebサイト(panda大学習帳外伝)の更新の頻度が高くないことが予想されることから、更新情報ファイルの作成のためのプログラムはWebサイトのシステム外かつGitHubリポジトリへのコミット等のタイミングとは無関係に手動で実行されるプログラムとしています。
なお、データベースにファイルの作成日時及び最終更新日時(のようなもの)が格納されている場合には、それらの中からもっとも新しい作成日時または更新日時(以下単に「更新日時」と書きます。)を読み出し、GitHub API呼び出し時のパラメータに追加することで、コミットの情報の取得範囲を更新日時以降に行われたコミットについての情報に限定します。このような条件の設定を行うことで、GitHub API経由で返される情報量を必要最低限に限定することができます。
また、データベースには更新日時を格納するためのテーブルを作成する必要があります(詳細は次節参照)。
コードを書いてみます。
前節で考察した要件を満たすコードのPython3による記述例は以下のような感じになります。
このファイルの実行に更新一覧への表示の対象としたいmarkdownファイル(複数でも可)を引数として指定すると、更新情報ファイルを標準出力に出力します。
上記コード中のコメントにも書きましたが、GitHub API用のクライアント鍵を格納したファイルは自分で勝手に定義できるものではなく、GitHubより取得する必要があります。その一方で、データベースへの接続のための設定ファイル(db_config.json)については別途定義する必要があります。
上記コードの実装の内容の大雑把な説明及び注意点は以下の通りです。
- 日時の処理にはpython-dateutilパッケージを主に使用しています(9行目等)。
- GitHub APIの実行の前にOAuth2による認証を行っています。これにより、APIの実行可能回数を引き上げていますが、この記事を最初に書いた時点(2019年7月)ではOAuth2による認証を行わなくてもAPIの実行自体は(回数の制限が厳しいですが、)可能なようです(18-24行目等)。
- 上記コード中及びデータベースへの格納時のファイルの作成日時及びファイルの更新日時は更新情報ファイルの作成時を除き、すべてUTCで処理しています(41-42行目等)。
- 47行目のようなpanda大学習帳外伝に特化した記述については大目にみてやっていただけると幸いです。🐼
- 削除されたファイルに対応するデータベース上のレコードは消去されます(67-72行目)。
- GitHub APIのCommit APIを実行する際にsinceパラメータを与えると、対応する値として指定された時刻以降のコミット情報を取得できます(80行目等)。
- ストアドプロシージャ的な引数の設定方法によってSQL文を実行する場合には、引数が1個の場合であっても(a,)のような形でタプルとして指定しないとエラーになるようです(ご参考的な注意点)。
- python-dateutilパッケージにおいて、タイムゾーンをUTCからローカルタイム(日本国内の場合ならJST)に変更するためにはdateutil.tz.tzlocal()を使用します(125,126行目)。
また、更新日時を格納するためのテーブルを作成するためのSQL文は、以下のような感じになります。filenameにUNIQUE制約を設定しています。
動作例。
前節のコードにより作成した更新情報ファイルをGitHubのGitHub Pages用のリポジトリにpushした結果得られる表示例は以下の通りになります。
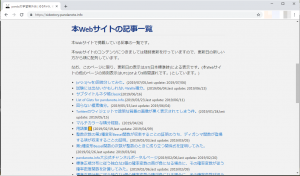
この記事の最初に示した表示例から比べると、ページの完成度が上がったように見えます。😎
panda大学習帳外伝における上記の表示例では、更新情報ファイルをトップページ用のmarkdownファイルからincludeするよう記述しています。トップページ用のmarkdownファイルから切り離すことにより、更新情報ファイルだけを再作成してpushさせることもできます。
まとめ
記事一覧に更新日時を追加すると見た目の完成度は上がりますが、コンテンツの情報の構成に必要な情報をGitHubの枠外で、それもデータベースを使って手動で管理するのはその分手間もかかります。
そこで、本WebサイトのWordpress用のデータベースに更新日時の管理用のテーブルを追加することと、GitHubのリポジトリへのcommit及びpushの直前に上記のPython3のプログラムを実行させる処理をまとめて実行するシェルスクリプトを作成することにより、運用にかかる手間の増加を必要最低限にすることを試みています。
本Webサイトの管理人たるpandaの経験上、ITシステム上においてあるまとまった処理を行わせるために複数個のコマンドを使用する運用としていると、後で運用の方法を忘れてしまったり、運用すること自体が嫌になってしまったりすることが多いような気がします。そこで、GitHub Pagesの更新に係る処理についてはできるだけ1個のコマンドを実行するだけで処理できる運用とすることにより、できるだけ末永く運用していきたいと考えております。🐼
この記事は以上です。
 GitHub APIを使って、GitHub上の自分のリポジトリの一覧を表示する簡易なウィジェットを作ってみた。
GitHub APIを使って、GitHub上の自分のリポジトリの一覧を表示する簡易なウィジェットを作ってみた。  OAuth2による認証を行った後、GitHub APIを実行してみた。
OAuth2による認証を行った後、GitHub APIを実行してみた。  GitHub APIを使ってGistにアップロードしたファイルのリストにひと手間かけたものを表示するページを作ったところ、割といいもの(本Webサイト比)ができた件。
GitHub APIを使ってGistにアップロードしたファイルのリストにひと手間かけたものを表示するページを作ったところ、割といいもの(本Webサイト比)ができた件。  GitHub Pagesで構築したWebサイトのURLをAmazonアソシエイトに追加登録の申請をしたところ、3回目の申請で追加が承認された件。
GitHub Pagesで構築したWebサイトのURLをAmazonアソシエイトに追加登録の申請をしたところ、3回目の申請で追加が承認された件。